You have an Azure subscription. You need to recommend a solution to provide developers with the ability to provision Azure virtual machines. The solution must meet the following requirements: - Only allow the creation of the virtual machines in specific regions. - Only allow the creation of specific sizes of virtual machines. What should you include in the recommendation?
A. Azure Resource Manager (ARM) templates
B. Azure Policy
C. Conditional Access policies
D. role-based access control (RBAC)
Azure Policies allows you to specify allowed locations, and allowed VM SKUs. Reference: https://docs.microsoft.com/en-us/azure/governance/policy/tutorials/create-and-manage
Question 152
DRAG DROP - You have an on-premises network that uses an IP address space of 172.16.0.0/16. You plan to deploy 30 virtual machines to a new Azure subscription. You identify the following technical requirements: - All Azure virtual machines must be placed on the same subnet named Subnet1. - All the Azure virtual machines must be able to communicate with all on-premises servers. - The servers must be able to communicate between the on-premises network and Azure by using a site-to-site VPN. You need to recommend a subnet design that meets the technical requirements. What should you include in the recommendation? To answer, drag the appropriate network addresses to the correct subnets. Each network address may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
Question 153
You have data files in Azure Blob Storage. You plan to transform the files and move them to Azure Data Lake Storage. You need to transform the data by using mapping data flow. Which service should you use?
A. Azure Databricks
B. Azure Storage Sync
C. Azure Data Factory
D. Azure Data Box Gateway
You can copy and transform data in Azure Data Lake Storage Gen2 using Azure Data Factory or Azure Synapse Analytics. Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-data-lake-storage
Question 154
You have an Azure subscription. You need to deploy an Azure Kubernetes Service (AKS) solution that will use Windows Server 2019 nodes. The solution must meet the following requirements: - Minimize the time it takes to provision compute resources during scale-out operations. - Support autoscaling of Windows Server containers. Which scaling option should you recommend?
A. Kubernetes version 1.20.2 or newer
B. Virtual nodes with Virtual Kubelet ACI
C. cluster autoscaler
D. horizontal pod autoscaler
Deployments can scale across AKS with no delay as cluster autoscaler deploys new nodes in your AKS cluster. Note: AKS clusters can scale in one of two ways: * The cluster autoscaler watches for pods that can't be scheduled on nodes because of resource constraints. The cluster then automatically increases the number of nodes. * The horizontal pod autoscaler uses the Metrics Server in a Kubernetes cluster to monitor the resource demand of pods. If an application needs more resources, the number of pods is automatically increased to meet the demand. Incorrect: Not D: If your application needs to rapidly scale, the horizontal pod autoscaler may schedule more pods than can be provided by the existing compute resources in the node pool. If configured, this scenario would then trigger the cluster autoscaler to deploy additional nodes in the node pool, but it may take a few minutes for those nodes to successfully provision and allow the Kubernetes scheduler to run pods on them. Reference: https://docs.microsoft.com/en-us/azure/aks/cluster-autoscaler
Question 155
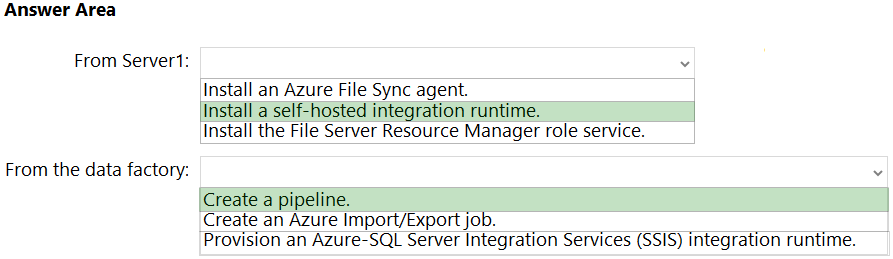
HOTSPOT - Your on-premises network contains a file server named Server1 that stores 500 GB of data. You need to use Azure Data Factory to copy the data from Server1 to Azure Storage. You add a new data factory. What should you do next? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Box 1: Install a self-hosted integration runtime. If your data store is located inside an on-premises network, an Azure virtual network, or Amazon Virtual Private Cloud, you need to configure a self-hosted integration runtime to connect to it. The Integration Runtime to be used to connect to the data store. You can use Azure Integration Runtime or Self-hosted Integration Runtime (if your data store is located in private network). If not specified, it uses the default Azure Integration Runtime. Box 2: Create a pipeline. You perform the Copy activity with a pipeline. Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-file-system
Question 156
You have an Azure subscription. You need to recommend an Azure Kubernetes Service (AKS) solution that will use Linux nodes. The solution must meet the following requirements: - Minimize the time it takes to provision compute resources during scale-out operations. - Support autoscaling of Linux containers. - Minimize administrative effort. Which scaling option should you recommend?
A. horizontal pod autoscaler
B. cluster autoscaler
C. virtual nodes
D. Virtual Kubelet
To rapidly scale application workloads in an AKS cluster, you can use virtual nodes. With virtual nodes, you have quick provisioning of pods, and only pay per second for their execution time. You don't need to wait for Kubernetes cluster autoscaler to deploy VM compute nodes to run the additional pods. Virtual nodes are only supported with Linux pods and nodes. Reference: https://docs.microsoft.com/en-us/azure/aks/virtual-nodes
Question 157
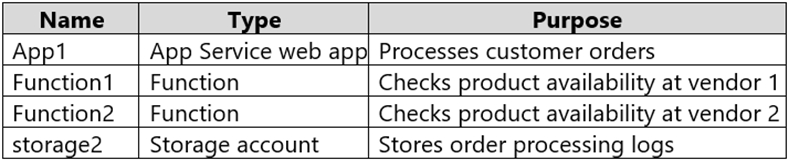
You are designing an order processing system in Azure that will contain the Azure resources shown in the following table. The order processing system will have the following transaction flow: - A customer will place an order by using App1. - When the order is received, App1 will generate a message to check for product availability at vendor 1 and vendor 2. - An integration component will process the message, and then trigger either Function1 or Function2 depending on the type of order. - Once a vendor confirms the product availability, a status message for App1 will be generated by Function1 or Function2. - All the steps of the transaction will be logged to storage1. Which type of resource should you recommend for the integration component?
A. an Azure Service Bus queue
B. an Azure Data Factory pipeline
C. an Azure Event Grid domain
D. an Azure Event Hubs capture
Azure Data Factory is the platform is the cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. Data Factory contains a series of interconnected systems that provide a complete end-to-end platform for data engineers. Reference: https://docs.microsoft.com/en-us/azure/data-factory/introduction
Question 158
You have 100 Microsoft SQL Server Integration Services (SSIS) packages that are configured to use 10 on-premises SQL Server databases as their destinations. You plan to migrate the 10 on-premises databases to Azure SQL Database. You need to recommend a solution to create Azure-SQL Server Integration Services (SSIS) packages. The solution must ensure that the packages can target the SQL Database instances as their destinations. What should you include in the recommendation?
A. Data Migration Assistant (DMA)
B. Azure Data Factory
C. Azure Data Catalog
D. SQL Server Migration Assistant (SSMA)
Migrate on-premises SSIS workloads to SSIS using ADF (Azure Data Factory). When you migrate your database workloads from SQL Server on premises to Azure database services, namely Azure SQL Database or Azure SQL Managed Instance, your ETL workloads on SQL Server Integration Services (SSIS) as one of the primary value-added services will need to be migrated as well. Azure-SSIS Integration Runtime (IR) in Azure Data Factory (ADF) supports running SSIS packages. Once Azure-SSIS IR is provisioned, you can then use familiar tools, such as SQL Server Data Tools (SSDT)/SQL Server Management Studio (SSMS), and command-line utilities, such as dtinstall/dtutil/dtexec, to deploy and run your packages in Azure. Reference: https://docs.microsoft.com/en-us/azure/data-factory/scenario-ssis-migration-overview
Question 159
You have an Azure virtual machine named VM1 that runs Windows Server 2019 and contains 500 GB of data files. You are designing a solution that will use Azure Data Factory to transform the data files, and then load the files to Azure Data Lake Storage. What should you deploy on VM1 to support the design?
A. the On-premises data gateway
B. the Azure Pipelines agent
C. the self-hosted integration runtime
D. the Azure File Sync agent
The integration runtime (IR) is the compute infrastructure that Azure Data Factory and Synapse pipelines use to provide data-integration capabilities across different network environments. A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network. It also can dispatch transform activities against compute resources in an on-premises network or an Azure virtual network. The installation of a self-hosted integration runtime needs an on-premises machine or a virtual machine inside a private network. Reference: https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
Question 160
You have an Azure Active Directory (Azure AD) tenant that syncs with an on-premises Active Directory domain. Your company has a line-of-business (LOB) application that was developed internally. You need to implement SAML single sign-on (SSO) and enforce multi-factor authentication (MFA) when users attempt to access the application from an unknown location. Which two features should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Azure AD Privileged Identity Management (PIM)
B. Azure Application Gateway
C. Azure AD enterprise applications
D. Azure AD Identity Protection
E. Conditional Access policies
D: The signals generated by and fed to Identity Protection, can be further fed into tools like Conditional Access to make access decisions, or fed back to a security information and event management (SIEM) tool for further investigation based on your organization's enforced policies. Note: Identity Protection is a tool that allows organizations to accomplish three key tasks: Automate the detection and remediation of identity-based risks. Investigate risks using data in the portal. Export risk detection data to your SIEM. E: The location condition can be used in a Conditional Access policy. Conditional Access policies are at their most basic an if-then statement combining signals, to make decisions, and enforce organization policies. One of those signals that can be incorporated into the decision-making process is location. Organizations can use this location for common tasks like: * Requiring multi-factor authentication for users accessing a service when they're off the corporate network. * Blocking access for users accessing a service from specific countries or regions. The location is determined by the public IP address a client provides to Azure Active Directory or GPS coordinates provided by the Microsoft Authenticator app. Conditional Access policies by default apply to all IPv4 and IPv6 addresses. Incorrect: Not A: Privileged Identity Management (PIM) is a service in Azure Active Directory (Azure AD) that enables you to manage, control, and monitor access to important resources in your organization. These resources include resources in Azure AD, Azure, and other Microsoft Online Services such as Microsoft 365 or Microsoft Intune. Reference: https://docs.microsoft.com/en-us/azure/active-directory/identity-protection/overview-identity-protection https://docs.microsoft.com/en-us/azure/active-directory/conditional-access/location-condition