Question 121
You work for a company that is developing a new video streaming platform. You have been asked to create a recommendation system that will suggest the next video for a user to watch. After a review by an AI Ethics team, you are approved to start development. Each video asset in your company’s catalog has useful metadata (e.g., content type, release date, country), but you do not have any historical user event data. How should you build the recommendation system for the first version of the product?
A. Launch the product without machine learning. Present videos to users alphabetically, and start collecting user event data so you can develop a recommender model in the future.
B. Launch the product without machine learning. Use simple heuristics based on content metadata to recommend similar videos to users, and start collecting user event data so you can develop a recommender model in the future.
C. Launch the product with machine learning. Use a publicly available dataset such as MovieLens to train a model using the Recommendations AI, and then apply this trained model to your data.
D. Launch the product with machine learning. Generate embeddings for each video by training an autoencoder on the content metadata using TensorFlow. Cluster content based on the similarity of these embeddings, and then recommend videos from the same cluster.
Question 122
You recently built the first version of an image segmentation model for a self-driving car. After deploying the model, you observe a decrease in the area under the curve (AUC) metric. When analyzing the video recordings, you also discover that the model fails in highly congested traffic but works as expected when there is less traffic. What is the most likely reason for this result?
A. The model is overfitting in areas with less traffic and underfitting in areas with more traffic.
B. AUC is not the correct metric to evaluate this classification model.
C. Too much data representing congested areas was used for model training.
D. Gradients become small and vanish while backpropagating from the output to input nodes.
Question 123
You are developing an ML model to predict house prices. While preparing the data, you discover that an important predictor variable, distance from the closest school, is often missing and does not have high variance. Every instance (row) in your data is important. How should you handle the missing data?
A. Delete the rows that have missing values.
B. Apply feature crossing with another column that does not have missing values.
C. Predict the missing values using linear regression.
D. Replace the missing values with zeros.
Question 124
You are an ML engineer responsible for designing and implementing training pipelines for ML models. You need to create an end-to-end training pipeline for a TensorFlow model. The TensorFlow model will be trained on several terabytes of structured data. You need the pipeline to include data quality checks before training and model quality checks after training but prior to deployment. You want to minimize development time and the need for infrastructure maintenance. How should you build and orchestrate your training pipeline?
A. Create the pipeline using Kubeflow Pipelines domain-specific language (DSL) and predefined Google Cloud components. Orchestrate the pipeline using Vertex AI Pipelines.
B. Create the pipeline using TensorFlow Extended (TFX) and standard TFX components. Orchestrate the pipeline using Vertex AI Pipelines.
C. Create the pipeline using Kubeflow Pipelines domain-specific language (DSL) and predefined Google Cloud components. Orchestrate the pipeline using Kubeflow Pipelines deployed on Google Kubernetes Engine.
D. Create the pipeline using TensorFlow Extended (TFX) and standard TFX components. Orchestrate the pipeline using Kubeflow Pipelines deployed on Google Kubernetes Engine.
Question 125
You manage a team of data scientists who use a cloud-based backend system to submit training jobs. This system has become very difficult to administer, and you want to use a managed service instead. The data scientists you work with use many different frameworks, including Keras, PyTorch, theano, scikit-learn, and custom libraries. What should you do?
A. Use the Vertex AI Training to submit training jobs using any framework.
B. Configure Kubeflow to run on Google Kubernetes Engine and submit training jobs through TFJob.
C. Create a library of VM images on Compute Engine, and publish these images on a centralized repository.
D. Set up Slurm workload manager to receive jobs that can be scheduled to run on your cloud infrastructure.
Question 126
You are training an object detection model using a Cloud TPU v2. Training time is taking longer than expected. Based on this simplified trace obtained with a Cloud TPU profile, what action should you take to decrease training time in a cost-efficient way?
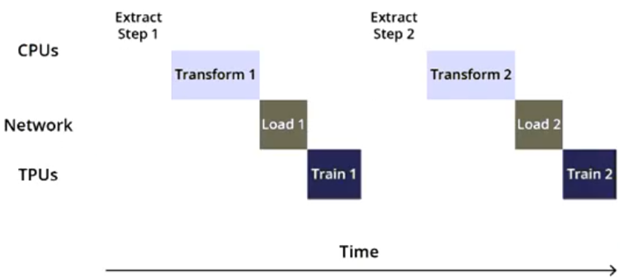
A. Move from Cloud TPU v2 to Cloud TPU v3 and increase batch size.
B. Move from Cloud TPU v2 to 8 NVIDIA V100 GPUs and increase batch size.
C. Rewrite your input function to resize and reshape the input images.
D. Rewrite your input function using parallel reads, parallel processing, and prefetch.
Question 127
While performing exploratory data analysis on a dataset, you find that an important categorical feature has 5% null values. You want to minimize the bias that could result from the missing values. How should you handle the missing values?
A. Remove the rows with missing values, and upsample your dataset by 5%.
B. Replace the missing values with the feature’s mean.
C. Replace the missing values with a placeholder category indicating a missing value.
D. Move the rows with missing values to your validation dataset.
Question 128
You are an ML engineer on an agricultural research team working on a crop disease detection tool to detect leaf rust spots in images of crops to determine the presence of a disease. These spots, which can vary in shape and size, are correlated to the severity of the disease. You want to develop a solution that predicts the presence and severity of the disease with high accuracy. What should you do?
A. Create an object detection model that can localize the rust spots.
B. Develop an image segmentation ML model to locate the boundaries of the rust spots.
C. Develop a template matching algorithm using traditional computer vision libraries.
D. Develop an image classification ML model to predict the presence of the disease.
Question 129
You have been asked to productionize a proof-of-concept ML model built using Keras. The model was trained in a Jupyter notebook on a data scientist’s local machine. The notebook contains a cell that performs data validation and a cell that performs model analysis. You need to orchestrate the steps contained in the notebook and automate the execution of these steps for weekly retraining. You expect much more training data in the future. You want your solution to take advantage of managed services while minimizing cost. What should you do?
A. Move the Jupyter notebook to a Notebooks instance on the largest N2 machine type, and schedule the execution of the steps in the Notebooks instance using Cloud Scheduler.
B. Write the code as a TensorFlow Extended (TFX) pipeline orchestrated with Vertex AI Pipelines. Use standard TFX components for data validation and model analysis, and use Vertex AI Pipelines for model retraining.
C. Rewrite the steps in the Jupyter notebook as an Apache Spark job, and schedule the execution of the job on ephemeral Dataproc clusters using Cloud Scheduler.
D. Extract the steps contained in the Jupyter notebook as Python scripts, wrap each script in an Apache Airflow BashOperator, and run the resulting directed acyclic graph (DAG) in Cloud Composer.
Question 130
You are working on a system log anomaly detection model for a cybersecurity organization. You have developed the model using TensorFlow, and you plan to use it for real-time prediction. You need to create a Dataflow pipeline to ingest data via Pub/Sub and write the results to BigQuery. You want to minimize the serving latency as much as possible. What should you do?
A. Containerize the model prediction logic in Cloud Run, which is invoked by Dataflow.
B. Load the model directly into the Dataflow job as a dependency, and use it for prediction.
C. Deploy the model to a Vertex AI endpoint, and invoke this endpoint in the Dataflow job.
D. Deploy the model in a TFServing container on Google Kubernetes Engine, and invoke it in the Dataflow job.