Question 201
You need to migrate a Redis database from an on-premises data center to a Memorystore for Redis instance. You want to follow Google-recommended practices and perform the migration for minimal cost, time and effort. What should you do?
A. Make an RDB backup of the Redis database, use the gsutil utility to copy the RDB file into a Cloud Storage bucket, and then import the RDB file into the Memorystore for Redis instance.
B. Make a secondary instance of the Redis database on a Compute Engine instance and then perform a live cutover.
C. Create a Dataflow job to read the Redis database from the on-premises data center and write the data to a Memorystore for Redis instance.
D. Write a shell script to migrate the Redis data and create a new Memorystore for Redis instance.
Question 202
Your platform on your on-premises environment generates 100 GB of data daily, composed of millions of structured JSON text files. Your on-premises environment cannot be accessed from the public internet. You want to use Google Cloud products to query and explore the platform data. What should you do?
A. Use Cloud Scheduler to copy data daily from your on-premises environment to Cloud Storage. Use the BigQuery Data Transfer Service to import data into BigQuery.
B. Use a Transfer Appliance to copy data from your on-premises environment to Cloud Storage. Use the BigQuery Data Transfer Service to import data into BigQuery.
C. Use Transfer Service for on-premises data to copy data from your on-premises environment to Cloud Storage. Use the BigQuery Data Transfer Service to import data into BigQuery.
D. Use the BigQuery Data Transfer Service dataset copy to transfer all data into BigQuery.
Question 203
A TensorFlow machine learning model on Compute Engine virtual machines (n2-standard-32) takes two days to complete training. The model has custom TensorFlow operations that must run partially on a CPU. You want to reduce the training time in a cost-effective manner. What should you do?
A. Change the VM type to n2-highmem-32.
B. Change the VM type to e2-standard-32.
C. Train the model using a VM with a GPU hardware accelerator.
D. Train the model using a VM with a TPU hardware accelerator.
Question 204
You want to create a machine learning model using BigQuery ML and create an endpoint for hosting the model using Vertex AI. This will enable the processing of continuous streaming data in near-real time from multiple vendors. The data may contain invalid values. What should you do?
A. Create a new BigQuery dataset and use streaming inserts to land the data from multiple vendors. Configure your BigQuery ML model to use the "ingestion" dataset as the framing data.
B. Use BigQuery streaming inserts to land the data from multiple vendors where your BigQuery dataset ML model is deployed.
C. Create a Pub/Sub topic and send all vendor data to it. Connect a Cloud Function to the topic to process the data and store it in BigQuery.
D. Create a Pub/Sub topic and send all vendor data to it. Use Dataflow to process and sanitize the Pub/Sub data and stream it to BigQuery.
Question 205
You have a data processing application that runs on Google Kubernetes Engine (GKE). Containers need to be launched with their latest available configurations from a container registry. Your GKE nodes need to have GPUs, local SSDs, and 8 Gbps bandwidth. You want to efficiently provision the data processing infrastructure and manage the deployment process. What should you do?
A. Use Compute Engine startup scripts to pull container images, and use gcloud commands to provision the infrastructure.
B. Use Cloud Build to schedule a job using Terraform build to provision the infrastructure and launch with the most current container images.
C. Use GKE to autoscale containers, and use gcloud commands to provision the infrastructure.
D. Use Dataflow to provision the data pipeline, and use Cloud Scheduler to run the job.
Question 206
You need ads data to serve AI models and historical data for analytics. Longtail and outlier data points need to be identified. You want to cleanse the data in near-real time before running it through AI models. What should you do?
A. Use Cloud Storage as a data warehouse, shell scripts for processing, and BigQuery to create views for desired datasets.
B. Use Dataflow to identify longtail and outlier data points programmatically, with BigQuery as a sink.
C. Use BigQuery to ingest, prepare, and then analyze the data, and then run queries to create views.
D. Use Cloud Composer to identify longtail and outlier data points, and then output a usable dataset to BigQuery.
Question 207
You are collecting IoT sensor data from millions of devices across the world and storing the data in BigQuery. Your access pattern is based on recent data, filtered by location_id and device_version with the following query:
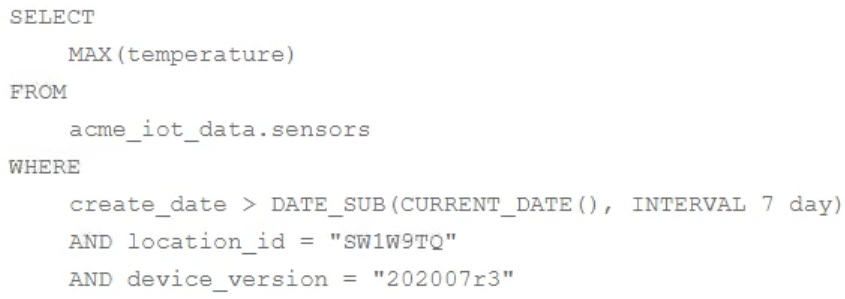
You want to optimize your queries for cost and performance. How should you structure your data?
A. Partition table data by create_date, location_id, and device_version.
B. Partition table data by create_date, cluster table data by location_id, and device_version.
C. Cluster table data by create_date, location_id, and device_version.
D. Cluster table data by create_date, partition by location_id, and device_version.
Question 208
A live TV show asks viewers to cast votes using their mobile phones. The event generates a large volume of data during a 3-minute period. You are in charge of the "Voting infrastructure" and must ensure that the platform can handle the load and that all votes are processed. You must display partial results while voting is open. After voting closes, you need to count the votes exactly once while optimizing cost. What should you do?
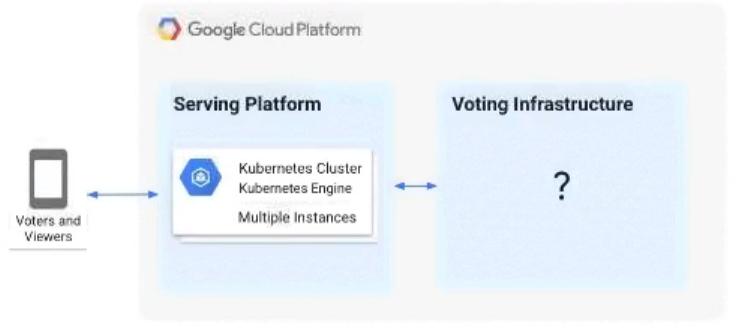
A. Create a Memorystore instance with a high availability (HA) configuration.
B. Create a Cloud SQL for PostgreSQL database with high availability (HA) configuration and multiple read replicas.
C. Write votes to a Pub/Sub topic and have Cloud Functions subscribe to it and write votes to BigQuery.
D. Write votes to a Pub/Sub topic and load into both Bigtable and BigQuery via a Dataflow pipeline. Query Bigtable for real-time results and BigQuery for later analysis. Shut down the Bigtable instance when voting concludes.
Question 209
A shipping company has live package-tracking data that is sent to an Apache Kafka stream in real time. This is then loaded into BigQuery. Analysts in your company want to query the tracking data in BigQuery to analyze geospatial trends in the lifecycle of a package. The table was originally created with ingest-date partitioning. Over time, the query processing time has increased. You need to copy all the data to a new clustered table. What should you do?
A. Re-create the table using data partitioning on the package delivery date.
B. Implement clustering in BigQuery on the package-tracking ID column.
C. Implement clustering in BigQuery on the ingest date column.
D. Tier older data onto Cloud Storage files and create a BigQuery table using Cloud Storage as an external data source.
Question 210
You are designing a data mesh on Google Cloud with multiple distinct data engineering teams building data products. The typical data curation design pattern consists of landing files in Cloud Storage, transforming raw data in Cloud Storage and BigQuery datasets, and storing the final curated data product in BigQuery datasets. You need to configure Dataplex to ensure that each team can access only the assets needed to build their data products. You also need to ensure that teams can easily share the curated data product. What should you do?
A. 1. Create a single Dataplex virtual lake and create a single zone to contain landing, raw, and curated data.
2. Provide each data engineering team access to the virtual lake.
B. 1. Create a single Dataplex virtual lake and create a single zone to contain landing, raw, and curated data.
2. Build separate assets for each data product within the zone.
3. Assign permissions to the data engineering teams at the zone level.
C. 1. Create a Dataplex virtual lake for each data product, and create a single zone to contain landing, raw, and curated data.
2. Provide the data engineering teams with full access to the virtual lake assigned to their data product.
D. 1. Create a Dataplex virtual lake for each data product, and create multiple zones for landing, raw, and curated data.
2. Provide the data engineering teams with full access to the virtual lake assigned to their data product.